超越开启与禁用,设计细粒度的 AI 治理体系

以前玩 MCP (Model Context Protocol),咱们的权限管理基本就是“非黑即白”:要么一把梭全开,让 AI 变成一个拿着核弹密码的“幻觉机器”;要么为了安全直接封死,把它变成一个只会聊天的复读机。
作为 MCP Hub 的设计者,我们有个直觉:“全开/全关”这种粗放逻辑,是对 AI 上下文容量最大的浪费。 这种管理方式忽略了一个核心事实——AI 的注意力(Attention)是有限的。当你向大模型塞入 50 个它在当前任务中根本用不到的工具描述(Tool Schema)时,你实际上是在人为制造“上下文熵”。
这一篇,我们聊聊 Mantra 如何通过细粒度治理,把 AI 从“噪音”中解放出来,打造一个真正纯净、高效的上下文环境。
痛点:被塞满的 System Prompt 与“注意力稀释”
现在的 MCP 客户端管理方式还挺原始的。你连上一个 Postgres Server,大部分客户端会一股脑把里面几十个工具描述全塞进 AI 的 System Prompt 里。
这会带来三个深坑:
注意力稀释 (Attention Dilution): 大模型的注意力也是有限的资源。如果你只想让 AI 查个表,它却看到了
create_index、delete_user甚至modify_schema。这些无关的 JSON-RPC 定义会像噪音一样塞满模型的上下文(这就是我们说的“上下文熵”),直接稀释 AI 的关注度,让它遵循复杂指令的准确率惨不忍睹。 图1: 被冗余工具塞满的上下文(Entropy 高) vs 经过 Mantra 清洗后的纯净上下文(Entropy 低)
图1: 被冗余工具塞满的上下文(Entropy 高) vs 经过 Mantra 清洗后的纯净上下文(Entropy 低)上下文窗口的“通货膨胀”: 没用的工具描述也在烧你的 Token。每个工具的 Schema 描述可能占据几百个 Token,在一个长达数小时的开发会话里,这种累积浪费非常惊人。用 Claude 3.5 Sonnet 或 GPT-4 这种按量计费的模型,你其实是在为“背景噪音”买单。
安全焦虑扼杀生产力: 正因为怕 AI 乱来,很多团队只敢给 AI 开放极少数工具。这种畏首畏尾的“安全焦虑”,让 AI 的强大能力废了一半。
说白了,治理可不只是为了限制,它的核心其实是“降噪”,顺便给 AI 真正放权。
核心逻辑:看得见,才管得住
MCP Hub 和普通 Client 的区别在于,它能“穿透”黑盒。
你在 Mantra 里刚拉起一个 MCP Server,网关就跟它“对上暗号”了。通过执行标准协议中的 list_tools、list_resources 和 list_prompts,网关能实时枚举出该服务的所有潜能。我们不玩虚的,直接穿透进程,把里面的每一个原子能力翻个底朝天。Mantra 会解析这些 JSON-RPC 响应,并用内置的语义引擎给每个工具打上标签。
有了这层解析,Mantra 就能把那些原本不可见的黑盒能力,清清楚楚地摆在控制台上。我们能一眼识别出哪些是“只读(Safe)”,哪些是“破坏性修改(Dangerous)”,这才是搞自动化治理的基础。
按需暴露:给 AI 做“上下文减法”
在 Mantra 的控制面板里,展开一个服务,不再是一个冷冰冰的开关,而是一张详尽的、可交互的能力清单。
1. 严格模式与智能分组
你可以精确控制 AI 在这一刻该“感知”到什么:
 图2: Mantra 控制面板 - 针对 Postgres 服务勾选 read_query 隐藏 drop_table
图2: Mantra 控制面板 - 针对 Postgres 服务勾选 read_query 隐藏 drop_table
- 项目级隔离 (Project-Based Isolation): Mantra 允许你创建不同的“工作空间(Workspaces)”。你可以配置在
Research模式下只加载 Wiki 和 Search Server,而在Production-DB模式下才加载数据库 Server。这种基于上下文的隔离,确保了 AI 不会在不该出现的时候看到不该看到的工具。 - 智能分组 (Semantic Grouping): 面对几十个工具,你不用自己挑。Mantra 会自动把工具归类为
Data Query、Schema Management等。你想一键开启“只读模式”?点一下就行,安全加固秒级完成。 - 工具白名单 (Tool Policy): 这是杀手锏。对于一个有 50 个工具的服务,你可能只想暴露 3 个查询接口(如
list_tables,read_query,describe_table)。当 Cursor 连接时,网关会动态过滤掉delete_row或drop_table。在 AI 看来,这个 Server 就只有这 3 个功能。上下文瞬间变纯净,推理精度直接拉满。
2. 多 Client 差异化授权
这是 MCP Hub 最爽的功能。你可以为不同工具定制不同的“面具”:
- Cursor (IDE): 开启“高信任模式”。因为你在盯着代码,所以可以给全量权限,让 AI 撒开了干。
- Gemini CLI (后台任务): 开启“严格审计模式”。只读,任何写操作直接在网关层拍死。
- 自动化脚本: 最小特权。发周报的脚本只准碰 Slack,绝对不准碰数据库。
这种“差异化授权”确保了安全和效率不用二选一,咱们全都要。
严格拦截:最后一道防线
即使有些“写操作”必须暴露,网关依然提供了一层物理防护。
1. 拦截器模式 (The Interceptor)
你可以为高危工具开启 “Always Confirm”。这就像是给 AI 加上了“两步验证”。 AI 尝试调用 execute_write 时,Mantra 会挂起请求,并在界面上直接弹窗:“Cursor 正在尝试修改数据库,是否批准?”。你不点头,AI 别想动。
 图3: 拦截器模式 - 事前拦截高危操作
图3: 拦截器模式 - 事前拦截高危操作
有了这个拦截器,安全管理就从以前那种“出事再查”的被动审计,变成了现在的“拦在门外”的主动防御。
2. 实时审计日志
配合实时日志,你能看清 AI 每一秒钟都在调哪个工具、传了什么参数。这种透明度,才是你敢把核心任务交给 AI 的底气。
Inspector:自带调试显微镜
开发者最怕的是“AI 报错了,但我不知道为啥”。是描述写歪了?还是参数对不上?
MCP Hub 内置了专业的 Inspector。你想调一下新写的工具,或者好奇 AI 为什么老是产生特定幻觉,直接打开 Inspector 观察原始 JSON-RPC 流。你甚至可以直接在界面上模拟 AI 调用:填参数、测逻辑,不用再去 IDE 里反复尝试。
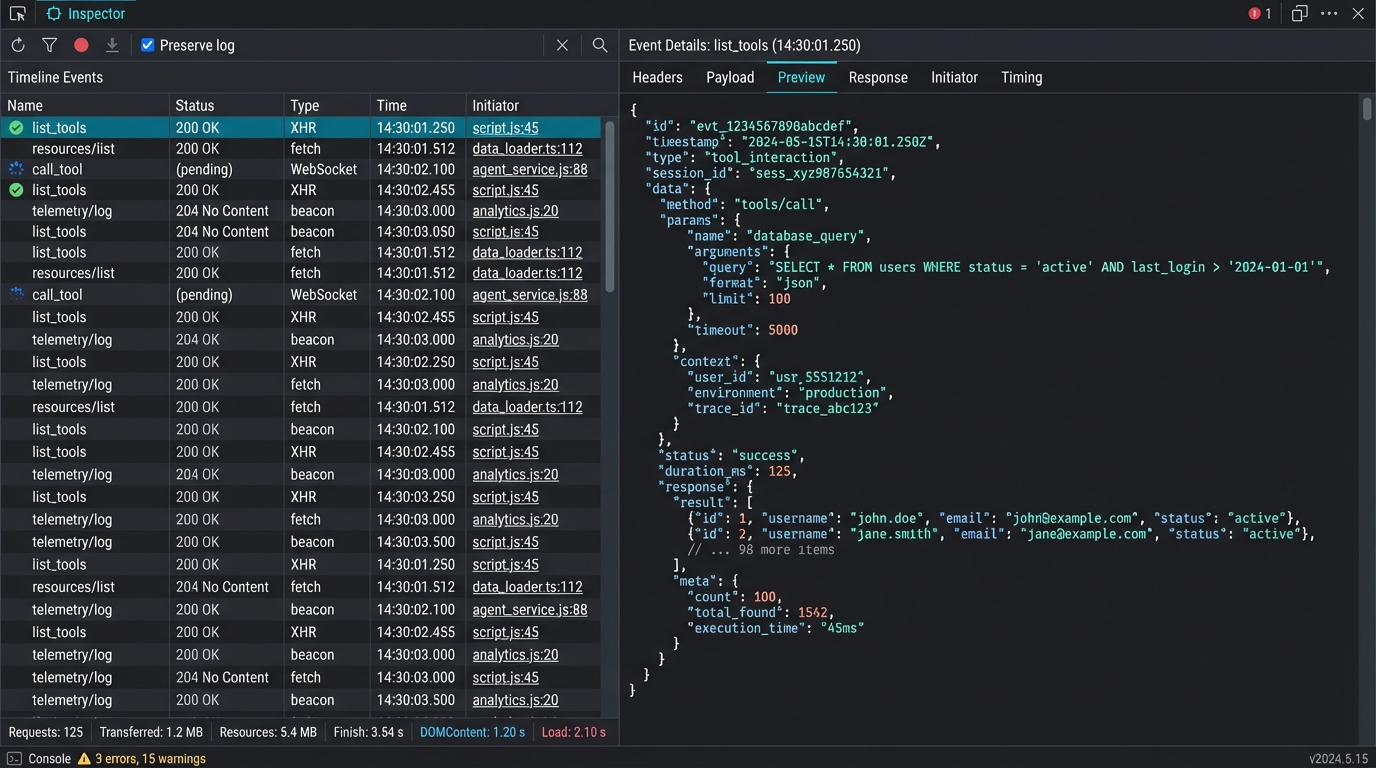 图4: 内置 Inspector - 可视化调试 JSON-RPC 流量
图4: 内置 Inspector - 可视化调试 JSON-RPC 流量
这种“所见即所得”的体验,真的让开发效率提升了一个量级。
结语:治理是为了更好的释放
讲真的,在 AI 时代,我们的挑战早就不再是怎么连上数据,难的是怎么在这一堆杂乱的上下文中保住 AI 的智商。
治理不是要束缚 AI,而是通过设定边界和剔除噪音,为它创造一个专注、纯净的工作环境。当干扰消失,AI 展现出的逻辑精度才是真正的生产力。
Mantra 想做的,就是这套 AI 时代的“新玩法”。
在系列文章的最后一篇中,我们将回归实战。我们将演示如何利用这套 Hub 体系,同时驱动 Cursor、Gemini CLI 和你自己的脚本。
敬请期待:《实战篇:One Hub, All Tools,用 Mantra 统一驱动你的 AI 工作流》。